Zero to Deployment and Evolution Data Catalog!
Which is? Open-source alternatives? How to implement? Challenges and more!

This publication is intended to shed light on the situation that “some” institutions have begun to understand and value their data as an internal product that will boost, qualify and distinguish their products concerning the market in the short term. This same company that, unfortunately, internally, each business area built its architecture, many times without a standard, without quality or basic sanitation and making the distribution in an archaic and slow way, full of “gambiaras” a veritable data slum.
In this chaotic situation, it is very common for business people to be somehow alienated, blaming situations of slowness in a certain “software” or solution, or they are “sure” that certain information does not exist in this entire zone.
How to change this situation? How to avoid “Shadow IT” with data? Prevent the “trafficking” of information?
An alternative is to understand what already exists, organize, dictionary, and catalog the available databases to distribute, and create an opportunity to foster a data-oriented organizational culture, that is, create a Data Hub.
These are some cases, according to LinkedIn engineers, of using a data catalog and a sample of the metadata they need:
Search and discovery: data schemas, fields, tags, usage information.
Access control: access control groups, users, policies.
Data lineage: pipeline executions, queries, API registrations, API schemas.
Compliance: Data Privacy Taxonomy / Compliance Annotation Categories.
Data management: data source configuration, ingest configuration, retention configuration, data purge policies (eg, for GDPR “Right To Be Forgotten”), data export policies (eg, for GDPR “Right To Access”).
AI explanation, reproducibility: resource definition, model definition, training execution runs, problem statement.
Data operations: pipeline runs, processed data partitions, data statistics.
Data quality: data quality rule definitions, rule execution results, data statistics.
Noting the growing market need, many communities, and companies worldwide will develop various solutions such as Airbnb’s Dataportal, Netflix’s Metacat, Uber’s Databook, LinkedIn’s DataHub, Lyft’s Amundsen, Spotify’s Lexikon, and Qlik Data Catalog.
Among these and many others, the ones that have stood out mainly in communities and companies that adopt and use open-source solutions are Amundsen from Lyft and DataHub from LinkedIn.
As Amundsen is a solution that was released before the DataHub and was incorporated into the LF AI Foundation, it gained a large community, and many companies use it in their production environments.
Looking at the DataHub, we can see that LinkedIn’s successful track record of open-source projects is repeating itself, like Kafka's case. In its first months, the project gained a large community, being adopted by many companies and even financial institutions that use it and actively contribute.

For experience, the number of integrations, and the wealthy documentation, I prefer DataHub and you?
DataHub is an open source metadata platform for the modern data stack.
Architecture
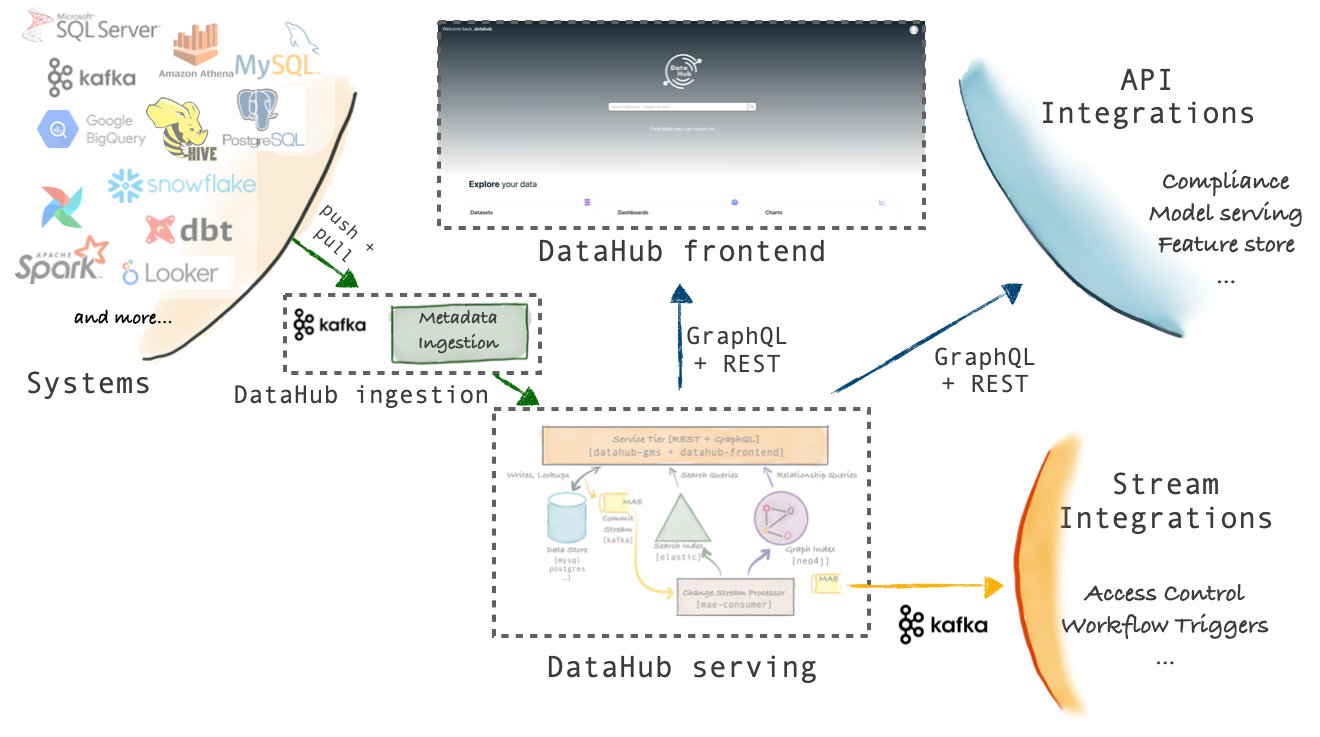
Its architecture can be divided into Ingestion, Serving, and FrontEnd:
- Ingestion Architecture:
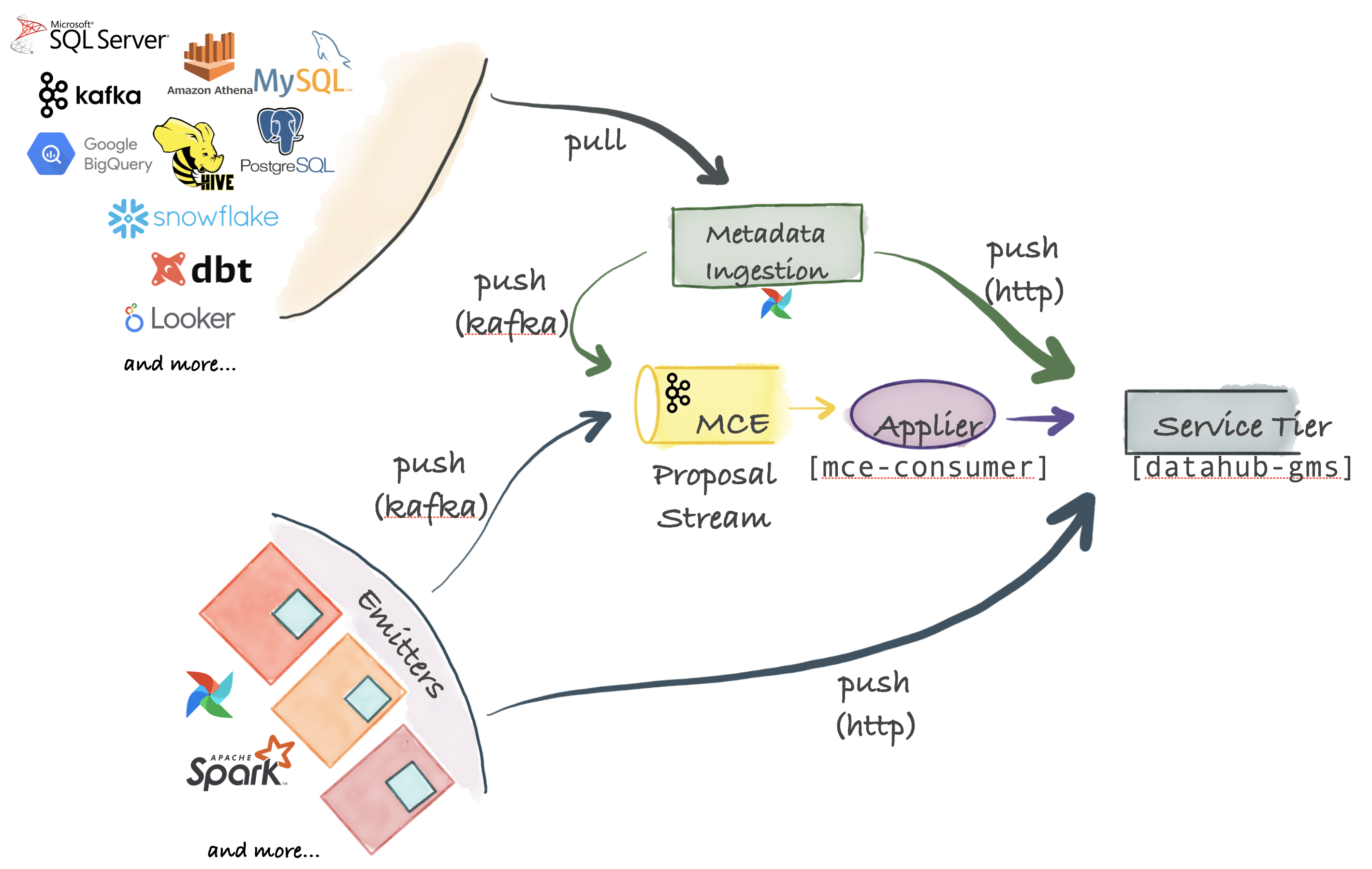
With a Python ingest system that plugs into different sources to extract metadata sent via HTTP or Kafka to a storage tier, these pipelines can be integrated into an Airflow for a scheduled ingest or capture lineage.
Serving architecture:
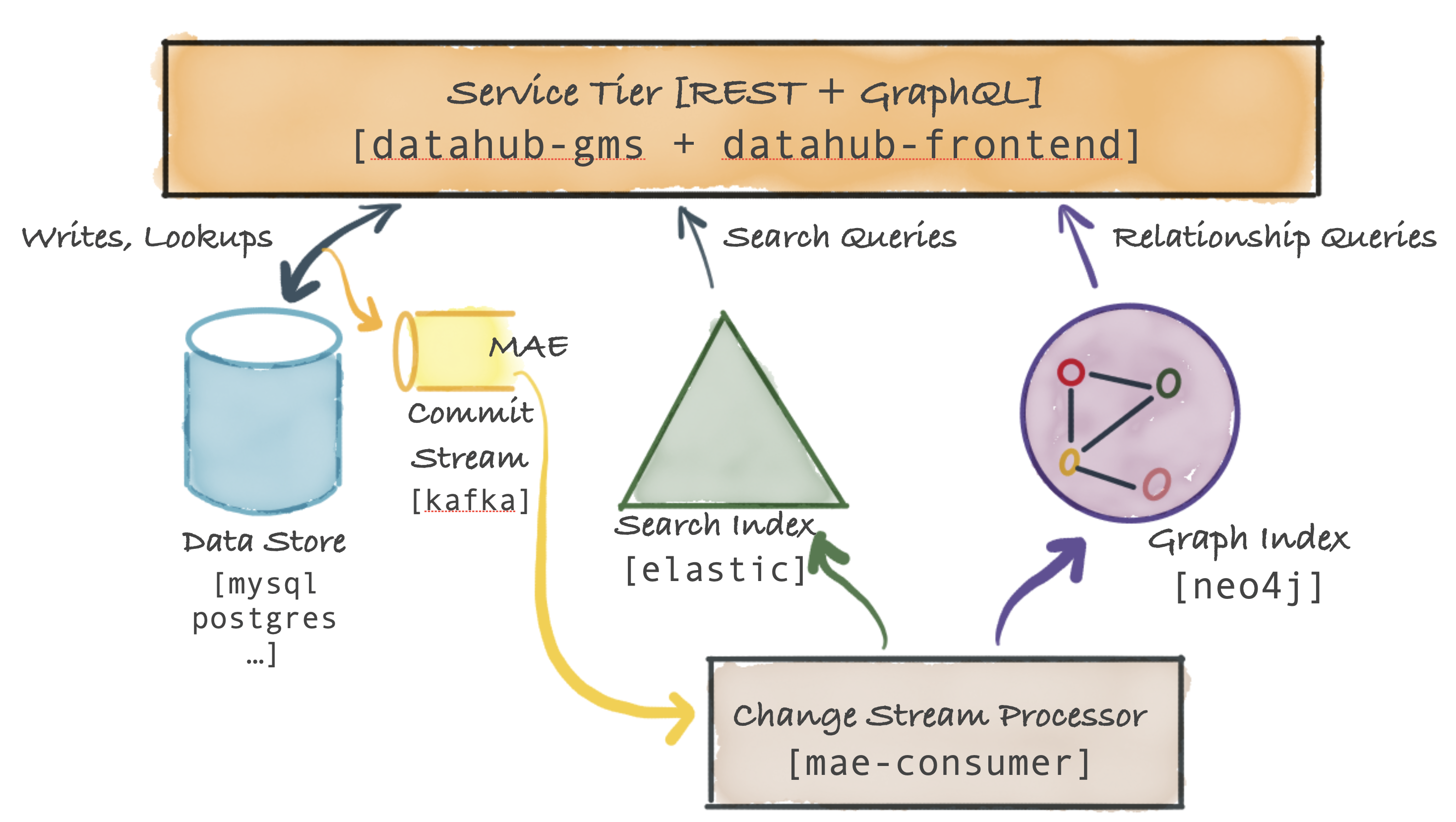
Metadata is persisted in a document store (it can be an RDBMS like MySQL, PostgreSQL, or a key-value store like Couchbase, etc.).
The DataHub has a Metadata Commit Log Stream (MAE), a service that makes it possible to check if there is a change in metadata and to initiate a real-time update reaction to the modification that happened.
- Front End Architecture: React App + Graphql + Images:
Your FrontEnd is built using React to enable:
Configurability: The customer experience must be configurable so that deployment organizations can adopt certain aspects to their needs. This includes the possibility of setting the theme/style, showing and hiding specific features, customizing copies and logos, etc.
Extensibility: Extending DataHub functionality should be as simple as possible. Making changes such as extending an existing entity and adding a new entity should require minimal effort and be well covered in the detailed documentation.
Integrations:
As a data catalog, one of its main adoption points is its number of out-of-the-box ingest solutions. With DataHub, it is only necessary to have the Docker installed, install a Python library, execute the YML configuration file passing to ingest category, access information such as username and password, and the “sink” destination.
List of integrations:
- Kafka
- MySQL
- Microsoft SQL Server
- Hive
- PostgreSQL
- Redshift
- AWS SageMaker
- Snowflake
- SQL Profiles
- Superset
- Oracle
- Feast
- Google BigQuery
- AWS Athena
- AWS Glue
- Druid
- SQLAlchemy
- MongoDB
- LDAP
- LookML
- Looker dashboards
- File
- dbt
- Google BigQuery
- Kafka Connect
Didn’t find your database or data source, an alternative to using SQLAlchemy to harvest metadata or ingest via Rest API or directly in DataHub’s internal Kafka.
In addition to integration with databases, APIs, Kafka, it is possible to conduct the integration and searches for information from artificial intelligence models.
Deploy:
Another concern when it comes to data catalog is where and how will it be installed? Your authentication? Backup and logs?
A personal concern is always to adopt solutions that can use in different environments; clouds and DataHub can be deployed locally via docker image, Kubernetes environment, AWS, and GCP. Your authentication can be integrated with JaaS Authentication, JaaS Authentication via React, Google Authentication, and Okta Authentication. The logs are in directories that can access remotely, and the data is saved in the database.
Local demonstration:

This is an example of performing a local PostgreSQL installation, creating a sample table, installing the DataHub, and ingesting PostgreSQL metadata into the DataHub. To perform this demonstration, it was necessary to have Docker, Git, and Python installed.
Deploy PostgreSQL using Docker compose:
Create the docker-compose.yml file with the following contents:
version: '3'
services:
postgres:
image: postgres:13.1
healthcheck:
test: [ "CMD", "pg_isready", "-q", "-d", "postgres", "-U", "root" ]
timeout: 45s
interval: 10s
retries: 10
restart: always
environment:
- POSTGRES_USER=root
- POSTGRES_PASSWORD=password
- APP_DB_USER=docker
- APP_DB_PASS=docker
- APP_DB_NAME=docker
volumes:
- ./db:/docker-entrypoint-initdb.d/
ports:
- 5432:5432
Run the following command:
docker-compose up
Using some database connection tool like Dbeaver, access PostgreSQL and create the following table:
CREATE TABLE COMPANY(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL,
JOIN_DATE DATE
);
DataHub Deploy
Having Python 3.6 installed or higher, run the commands below in the terminal:
python3 -m pip install --upgrade pip wheel setuptools
python3 -m pip uninstall datahub acryl-datahub || true
python3 -m pip install --upgrade acryl-datahubdatahub version
Install the DataHub CLI on your terminal:
datahub docker quickstart
Go to http://localhost:9002; your username and password will be “datahub”, without the quotes.
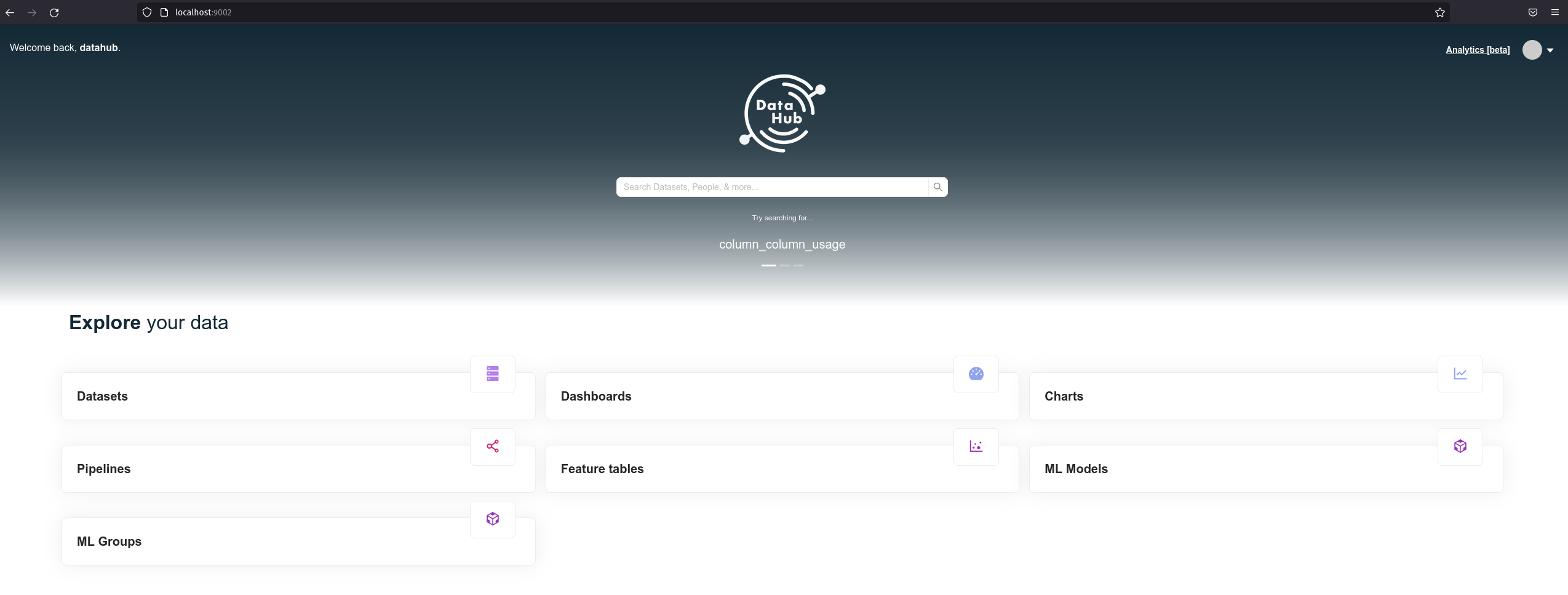
We have our DataHub and PostgreSQL running:

Ingest PostgreSQL metadata into DataHub:
Clone the DataHub project:
git clone https://github.com/linkedin/datahub.git
Navigate to the ingest scripts folder:
cd datahub/metadata-ingestion/scripts
Create the metadata_ingest_from_postgres.yaml file with the following content:
source:
type: postgres
config:
username: root
password: password
host_port: localhost:5432
database: postgres
database_alias: postgrespublic
include_views: True
sink:
type: "datahub-rest"
config:
server: "http://localhost:8080"
Run the command below:
./datahub_docker.sh ingest -c ./metadata_ingest_from_postgres.yml
From the command above, all metadata will be ingested and will be available for access:
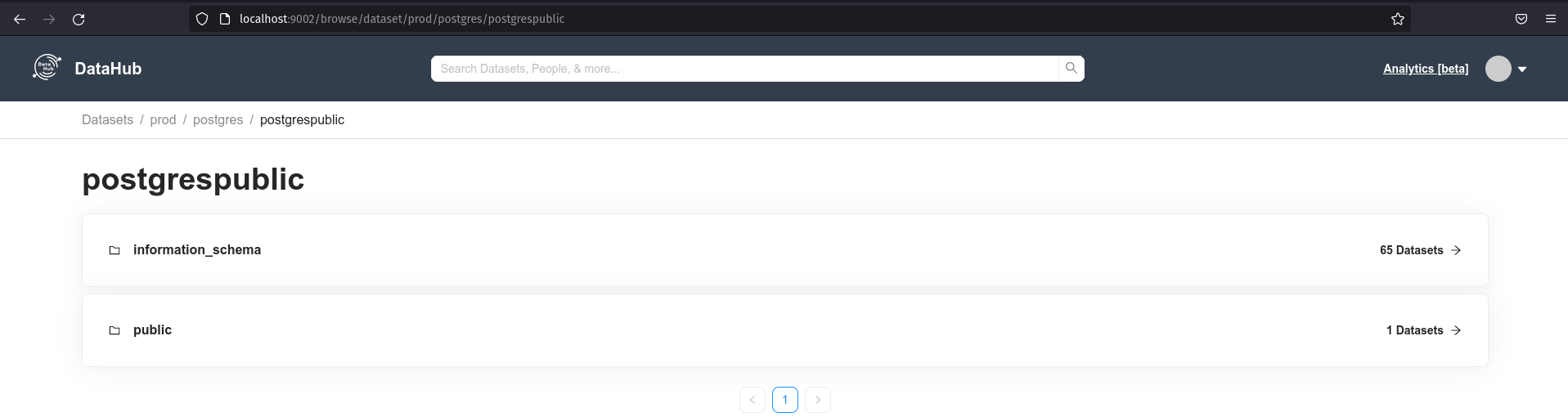
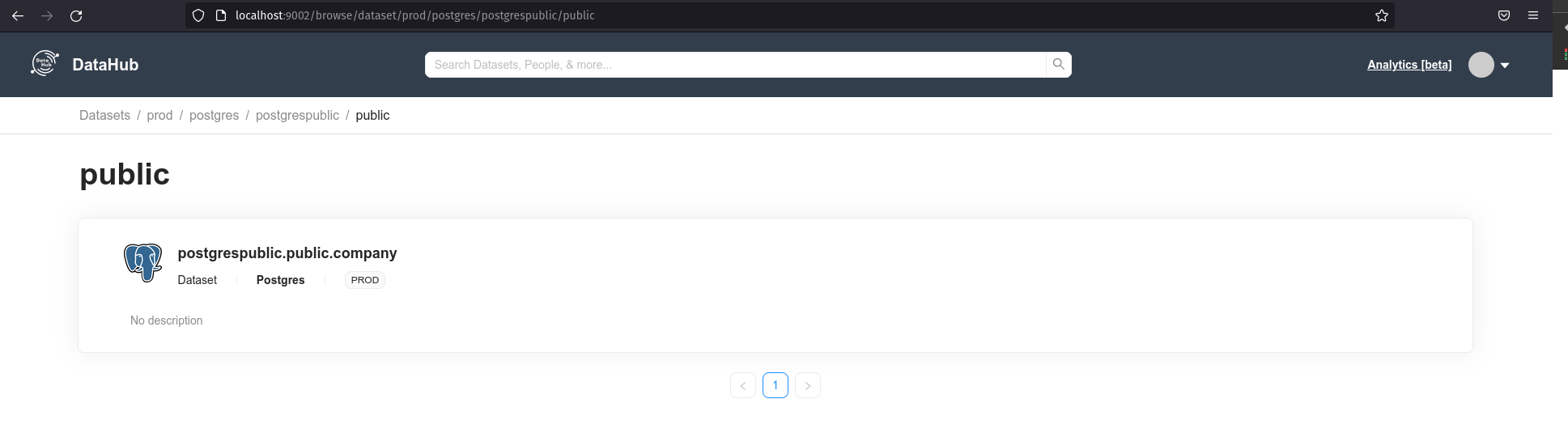
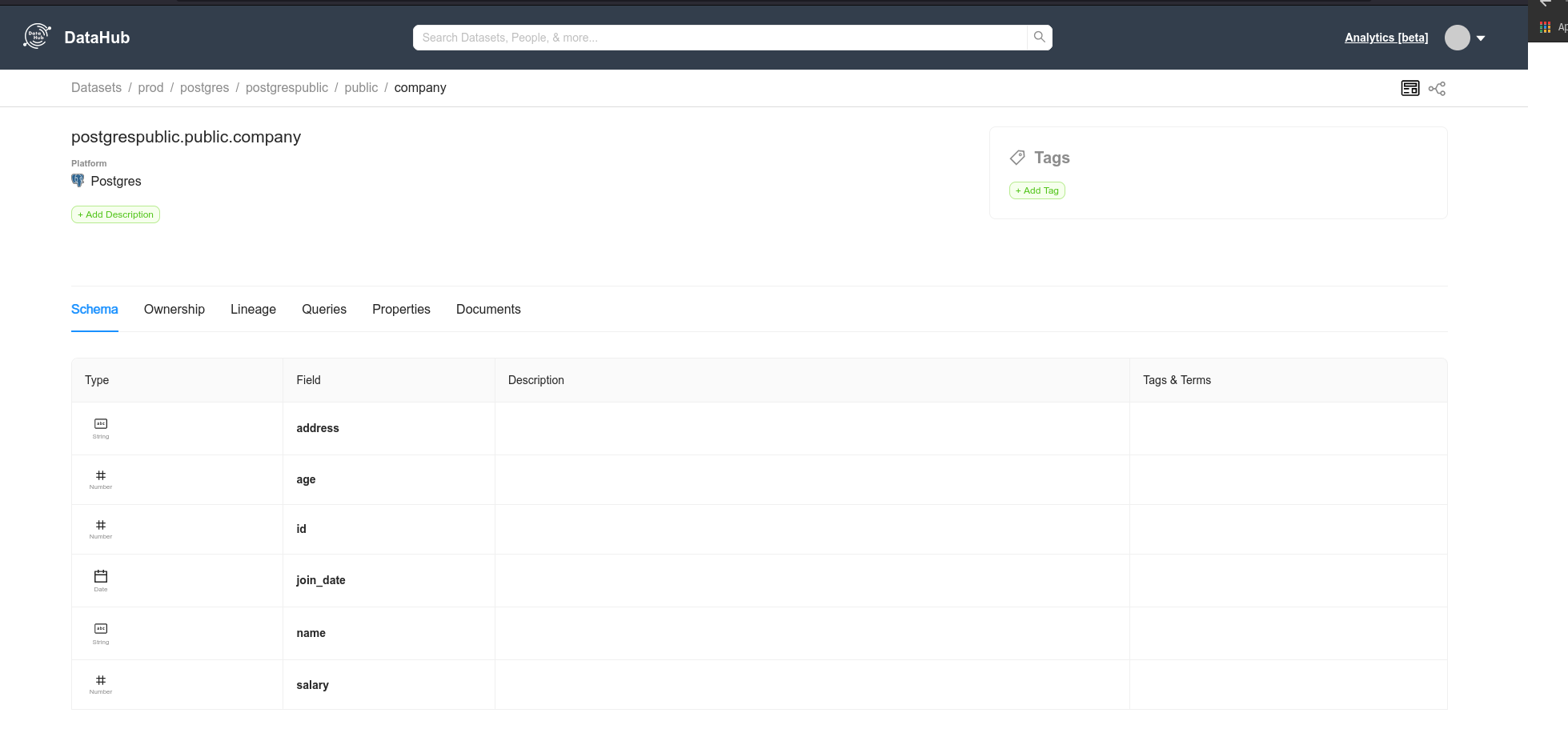
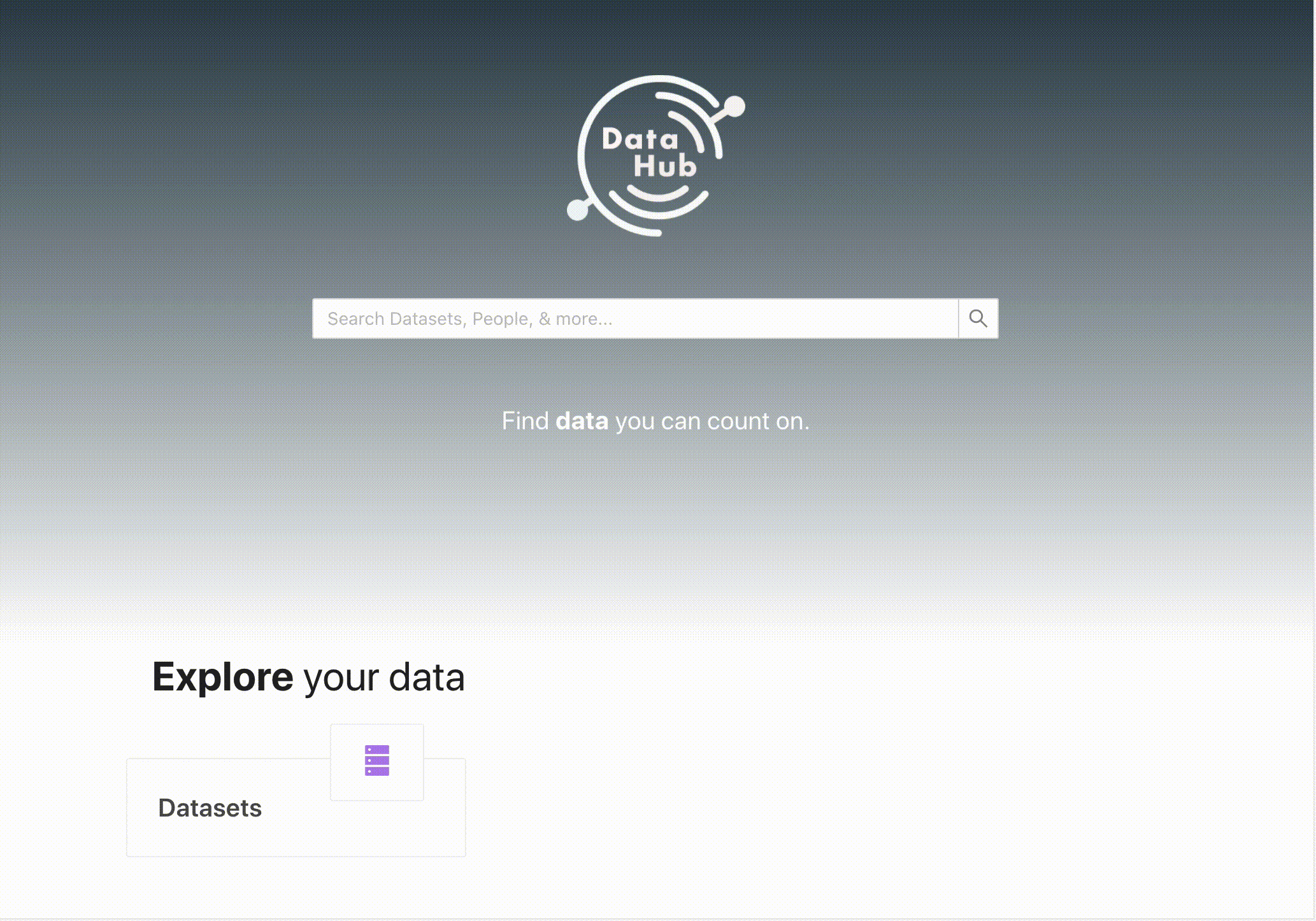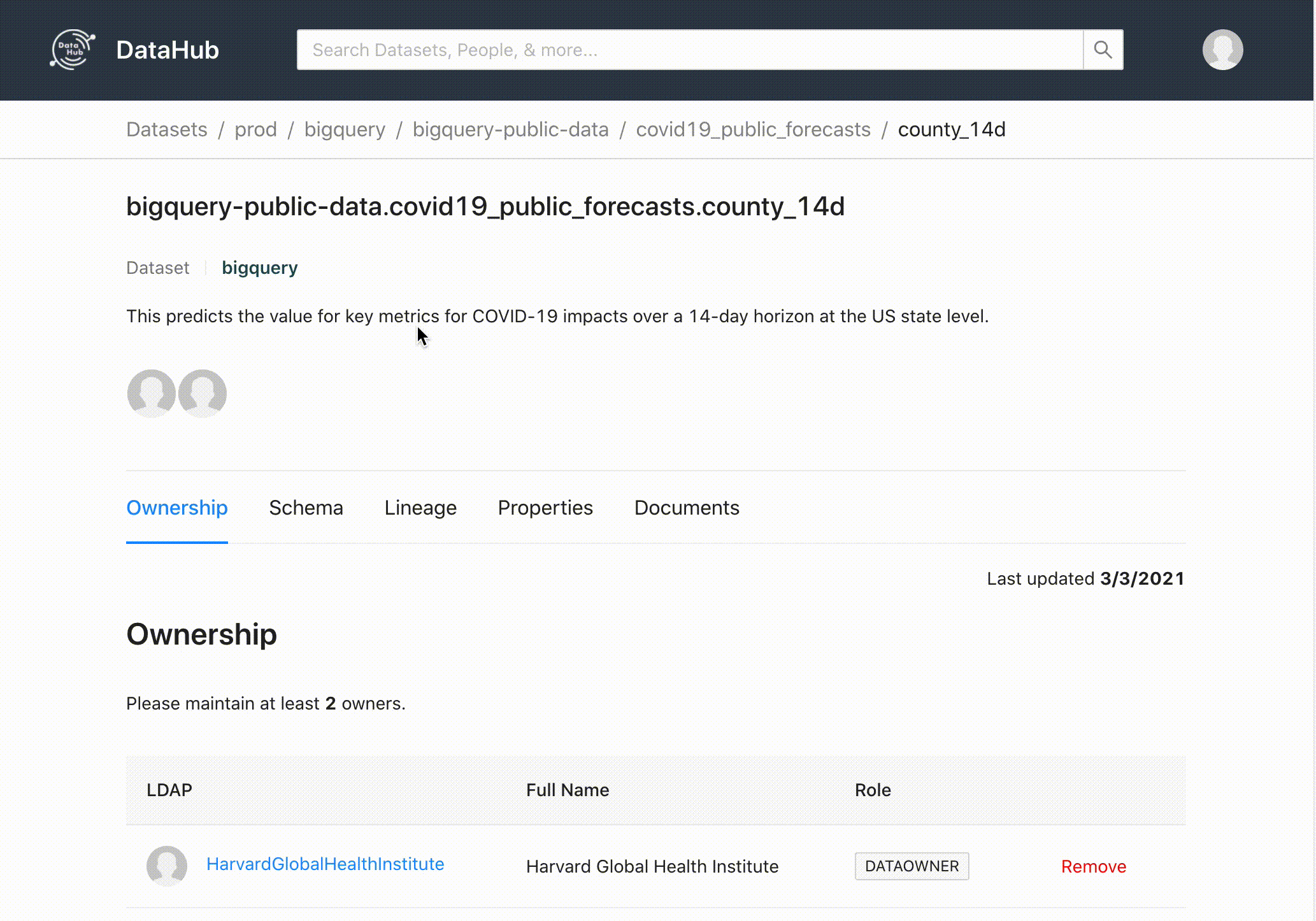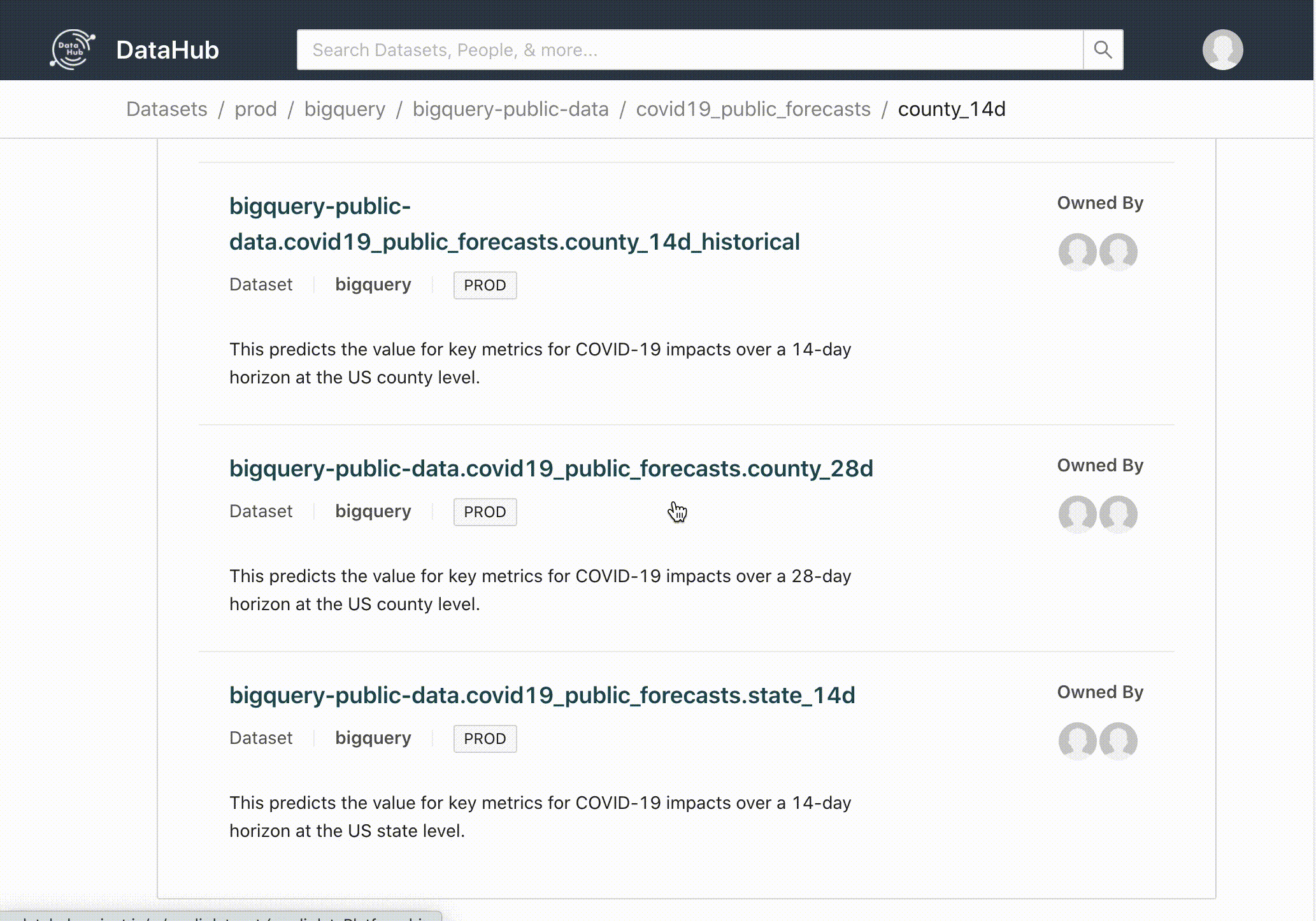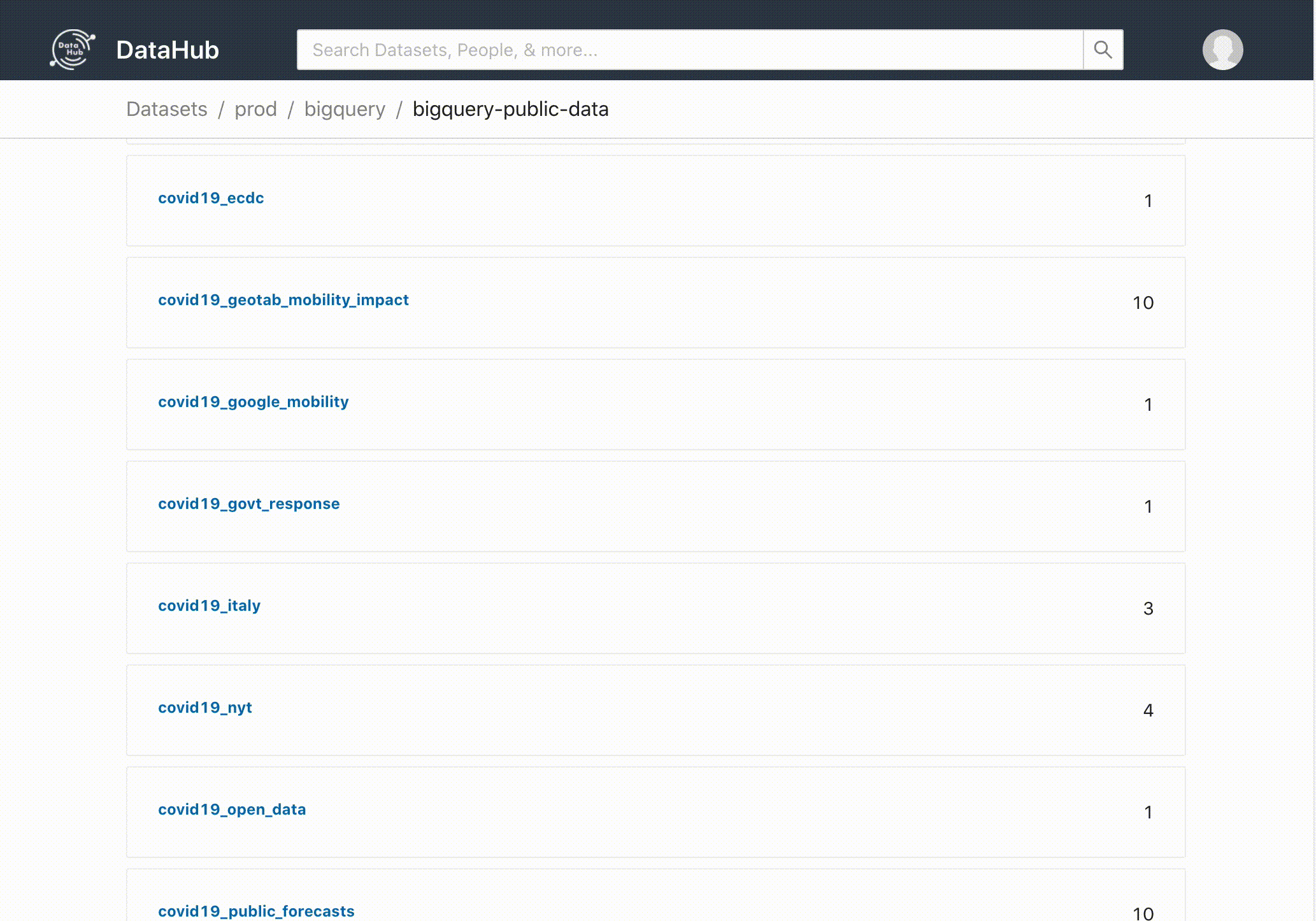
In addition to the collected metadata, it is possible to place a description and tags for the schemas, tables, and columns; find out your owner's “Ownership”, pedigree, main queries, properties, and additional documentation links.
Conclusion:
Structure the universe of initially chaotic data can be a very complex task. The first step will be to conduct an immersion and cataloging of the data to restructure a scenario where there is better governance and information quality.
A vision of an ideal data mesh architecture:
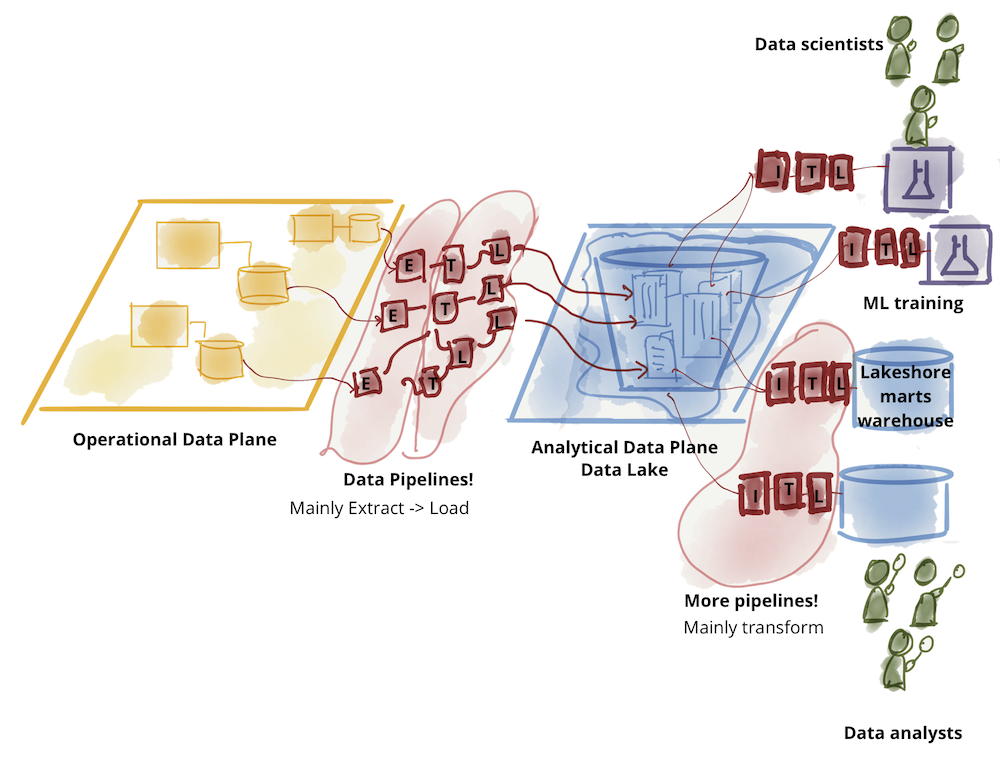
DataHub is a powerful data catalog solution that, in addition to integrating with different databases, enables data lineage and even cataloging of artificial intelligence models. However, this solution is not magic; it is necessary to monitor and ingest data such as field descriptions and access management.
“Without data, you’re just another person with an opinion.”, W. Edwards Deming
References:

Follow me on Medium :)




