Airbyte: Data Integration / CDC Solution for Modern Data Teams!
Create your simple real-time data streams with an easy and accessible platform!

This platform intends to present the data integration scenario using the Airbyte solution, create data capture streams, and more.
Many associations expect that they soil diverse structured and unstructured data sources with specific forms of access and control. In this scenario, it is prevalent to see a series of data flow, often arranged in solutions for big data scenarios such as Apache Spark.
Due to lack of technical knowledge in other solutions and exemplary leadership, it is elementary and familiar for data teams to start using a solution provided as a silver bullet until it becomes transparent, uses an unnecessary infrastructure, and affects other processes much more approved.
Weighing in a solution for simple data integration, almost a change capture that can be used in different clouds like GCP and AWS, simple to use so that users have no difficulties and are easy to maintain, discover Airbyte.

Airbyte is an open-source project with several connectors, the ability to perform data normalization, and an active community with more than four thousand contributions.
How is Airbyte different from other ETL / ELT tools? Traditional tools, such as Fivetran or StitchData, are closed-source and cloud-based. Your prices are indexed according to the volume of data you replicate. Open source allows Airbyte to offer better prices and cover all your connector needs, given the long tail of integrations, and all without any blocking mechanism. How long does it take to replicate data with Airbyte? There are several ways to deploy Airbyte. For example, using Docker compose, it takes 2 minutes to replicate data from Salesforce to Snowflake.
Deploy Location:
With compose Docker installed, follow the steps below:
Using git, copy the project to your environment:
git clone https://github.com/airbytehq/airbyte.git
Enter the folder:
cd airbyte
Lift and enjoy Airbyte! :)
docker-compose up
Go to http://localhost:8000 and start moving data! :),
In addition to being able to deploy to clouds, this can be done in Kubernetes as well:

Data source connectors:
These are the available connectors, but many others are already under construction and will be integrated into new versions:
Possible data destinations:
Other Connectors:
After looking at these connectors, you can’t find yours or need to build a new custom connector; you can create your connector using Python or Javascript.

Sync Modes in Airbyte:
A connection is a setting to synchronize data between a source and a destination. To set up a connection, a user must set up things like:
Sync schedule: when triggering a data synchronization.
Destination Namespace and stream names: where the data will end up being written.
A catalog selection: which streams and fields to replicate from the source.
Sync mode: how streams should be copied (read and write).
Optional transformations: Converting data from Airbyte protocol messages (raw JSON blob) into some other data representations.
In addition to these necessary settings, there are modes:
- Full Refresh-Overwrite:
Full Refresh mode is a more straightforward method than Airbyte uses to sync data, as it always retrieves all requested available information from the source, regardless of whether it has been synced before. This contrasts with incremental sync, which does not sync data that has been synced before. In the “Overwrite” variant, new syncs will destroy all data in the existing target table and then extract the latest data. Therefore, data removed from the source after the old sync will be deleted from the target table.
- Full Refresh-Append:
In the “Append” variant, new syncs will take all the data from the sync and append it to the destination table. Therefore, if you sync similar information multiple times, each sync will create duplicates of existing data.
- Incremental Sync-Append:
Airbyte supports data synchronization in incremental add mode if synchronization only replicates new or modified data. This prevents re-fetching data that you’ve already copied from a source. If the sync is running for the first time, it is equivalent to a complete refresh, as all data is new.
In this incremental, records in the warehouse target will never be deleted or modified. A copy of each new or updated record is appended to the data in the Warehouse. This means that you can find multiple copies of the same record in the destination warehouse. We offer an “at least once” guarantee to replicate every record present when synchronization is performed.
- Incremental Sync -Deduped History:
Airbyte supports data synchronization in incremental de-duplication history mode, ie:
Incremental: means to sync only new replicated or modified data. This prevents re-fetching data that you’ve already copied from a source. If the sync is running for the first time, it will be equivalent to a Full Refresh, as all data will be considered new.
Deduped: means the data in the final table will be unique by primary key (unlike Append modes). This is determined by sorting the data using the cursor field and keeping only the most recent duplicate data row. In dimensional Data Warehouse jargon defined by Ralph Kimball, this is referred to as a Type 1 Slowly Changing Dimension (SCD) table.
History: An additional intermediate table is created where data is being continually appended (with duplicates just like modes append) using the primary key field; it identifies the effective start and end dates for each row of a record. In dimensional Data Warehouse jargon, this is a Type 2 Slowly Changing Dimension (SCD) table.
In this incremental, records in the warehouse target will never be deleted from the history tables (named with an _scd suffix), but they might not exist in the final table. A copy of each new or updated record is appended to historical data in the Warehouse. The end date column is changed when a new version of the same record is inserted to denote the effective date ranges. This means that you can find multiple copies of the same record in the destination warehouse. We offer an “at least once” guarantee to replicate every record present when synchronization is performed.
On the other hand, records at the final destination can potentially be deleted as they are duplicated. You should not find multiple copies of the same primary key as they must be unique in this table.

Basic normalization in Airbyte
When you run your first Airbyte sync without essential normalization, you’ll notice that your data is written to your destination as a column of data with a JSON blob that contains all of your data. This is the _airbyteraw table you might have seen before. Why did we create this table? A fundamental tenet of the ELT philosophy is that data must be untouched as it moves through stages E and L so that the raw data is always accessible. If there is an unmodified version of the information on the destination, it can be transformed again without resynchronizing the data.
If you have Basic Normalization enabled, Airbyte automatically uses this JSON blob to create a schema and tables with your data in mind, converting it to your target’s format. This runs after syncing and can take a long time if you have a lot of synced data. If you don’t enable essential normalization, you’ll have to transform the JSON data for that column yourself.
Essential normalization uses a fixed set of rules to map a JSON object from a source to the native types and formats for the target. For example, if a source outputs data similar to this:
{
"make": "alfa romeo",
"model": "4C coupe",
"horsepower": "247"
}
Target connectors produce the following raw table in the target database:
CREATE TABLE “_airbyte_raw_cars” (
-- metadata added by airbyte
“_airbyte_ab_id” VARCHAR,
-- uuid value assigned by connectors to each row of the data written in the destination.
“_airbyte_emitted_at” TIMESTAMP_WITH_TIMEZONE,
-- time at which the record was emitted.
“_airbyte_data” JSONB — data stored as a Json Blob.
);
So, essential normalization would create the following table:
CREATE TABLE "cars" (
"_airbyte_ab_id" VARCHAR,
"_airbyte_emitted_at" TIMESTAMP_WITH_TIMEZONE,
"_airbyte_cars_hashid" VARCHAR,
"_airbyte_normalized_at" TIMESTAMP_WITH_TIMEZONE, -- data from source
"make" VARCHAR,
"model" VARCHAR,
"horsepower" INTEGER
);
Implementation example:
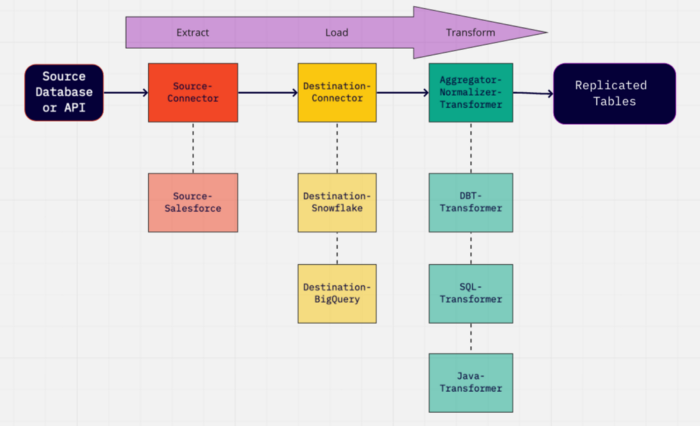

Change Data Capture (CDC) in Airbyte:
Orchestration for synchronization is like database sources, not like CDC. After selecting a sync interval, syncs start regularly. The Airbyte reads the data from the log up to the moment the synchronization was started. We do not treat CDC sources as infinite streaming sources. You must ensure that your schedule for performing these synchronizations is frequent enough to consume the generated logs. The first time the synchronization runs, a snapshot of the current state of the data will be taken. This is done using “SELECT” instructions and is effectively a complete upgrade. Subsequent syncs will use the logs to determine the changes since the last sync and update them. Airbyte keeps track of the current record position between syncs.
Single sync might have some tables set up for full update replication and some for incremental. If CDC is configured at the source level, all tables with Incremental selected will use CDC. All “Full Refresh” tables will be replicated using the same process from non-CDC sources. However, these tables will still include CDC metadata columns by default.
The Airbyte protocol issues font records. Records for “UPDATE” statements appear the same as records for “INSERT” statements. Airbyte supports different options of syncing this data to destinations using primary keys, so you can choose to append this data, delete it on-site, etc.
Limitations:
Incremental CDC only supports tables with primary keys.
A CDC source can still choose to replicate tables without primary keys like “Full Refresh” or a non-CDC source can be configured for the same database to replicate tables without primary keys using standard incremental replication.
Data must be in tables, not views.
The modifications you are trying to capture must be done using “DELETE / INSERT / UPDATE” for example, changes made to “TRUNCATE / ALTER” will not appear in the logs; therefore, in your destination.
Airbyte does not automatically support schema changes for “CDC” fonts. I recommend resetting and resynchronizing the data if you make a schema change.
There are database-specific limitations. See the individual connector documentation pages for more information.
Records produced by “DELETE” statements contain only primary keys. All other data fields are undefined.

“With Great Powers Come Great Responsibilities” -Stan Lee.
Data Pipelines may not be a problem today, but if they are not well-structured and documented, they can become a huge problem and even a bottleneck for your organization. I see Airbyte as a project that works very well for capturing and integrating data from various sources for scenarios that need real-time information where we don’t want to perform complex normalization and synchronizations.
In addition to this fantastic tool, there are many others with specific purposes that have been gaining market and you, how do you integrate data within your company? When your silver bullet no longer works, what will you do?
References:

Thanks for your reading, follow me on Medium :)




